Even I get surprised by how often I dream about my Thinkpad x220. #dreamsaboutmyex 2018-01-12
Even I get surprised by how often I dream about my Thinkpad x220. #dreamsaboutmyex
tagged as
Even I get surprised by how often I dream about my Thinkpad x220. #dreamsaboutmyex
I am a fairly sanguine UK rail commuter. I do not understand why they schedule the annual price hike for exactly the same week the holiday maintenance work is likely to have overrun, affecting all the services. Surely it would make more sense to raise the price at the start of the financial year, in April?
Old Street station has a popup "Black Mirror" shop. I am not sure how I feel about this. I am fairly sure I know how Dan Ashcroft would feel about this.
Day one of no twitter feels very strange. This gives me some confidence that it is probably a useful exercise.
I'm not a very Windows-focused computer user. In fact I think the last era I used it really extensively, with any expertise, was in the 16-bit era of Windows 3.1 - 3.11. I quite liked those versions, which operated somewhat more like an integrated interface SDK for MS-DOS than an independent operating system. As the commercial internet boom took hold, and work became focused almost entirely on building web applications targetting UNIX-like deployment environments, (typically linux), I shifted over to working natively in that environment, and never looked back. So, I don't really know how to use modern Windows at all comfortably, and I don't have any personal ease when working with it's native interface.
Normal development tooling for me is a simple GUI windowing environment, running on Debian linux. I (still) use GNU emacs or increasingly zed for almost everything that isn't in a web browser, alongside a handful of running terminals, an email client, and some kind of file browser, and music player and that's about it. My development projects I tend to isolate into containers, using lxc/lxd and more lately, incus, to give me "lightweight" virtual hosts nested on my computer, connected with a virtual ethernet LAN. It effectively is a local 'cloud', offering dependency and process isolation for your work, and powerful features like snapshot/checkpointing, image templating. What I particularly like about the incus approach, compared say to other container systems, like docker, is the abstraction is well suited to longer-lived, stateful development systems - you partition one linux system into a few dozen smaller more specialised linux systems with the state hidden from each other. The unit of containment is 'operating system'. Whereas with docker-like containment, I think the unit of abstraction is something more like 'one process, with all of it's dependencies bundled', which makes more sense to me for one-shot tasks, or often as a deployment target.
Back in the 90s(!), when computers were a lot less powerful than they are today, I commonly used to use emacs 'tramp' or Ange-FTP modes, to develop remotely on a development or staging server, from a thinner client. Now I use the same approach, and the same tools, to develop on my container environments, effectively treating them like a 'remote' host, even though they're only conceptually remote. Tramp, just like most of emacs, is a kludgey wonder - it encodes the information about remote endpoints using pseudo-paths, like /ssh:user@host:/path/to/something , and emacs just works out how to edit your files. Under the hood, it strings together a glue of subprocesses and temporary file copies and the like, to take your editing and reflect it on the remote environment. And not just files. This is emacs! Almost everything in emacs works tramp-aware, so you can browse the remote filesystem using dired - launch processes for compilation or linting, use git workspaces with magit-mode, run interactive shells and debuggers, build and run your projects, it has extremely high levels of DWIM. The main price you pay is occasional latency, as things shuttle back and forth, or buffer in and out of pipes, but I’m very used to this. And compared with the days when I used to use tramp to work over dialup(!) links to servers, this modern container approach is practically turbo-charged. Eat my dust!
Zed simililarly offers remote editing using ssh connections, with a slightly different architecture. The zed remote feature is a little more modern, like VSCode - it downloads a headless install of the editor on the remote after you ssh to it, and then proxies to that backend using it's own protocols over ssh. The net effect is the same though, you work on your local keyboard screen and mouse, but your working environment is in the remote hosts. An advantage zed offers over tramp's elegant hackaround is that the latency is considerably reduced, it's not copying files backward and forwards and slowly lauching tasks in shells. A disadvantage zed offers, is that it's not emacs and it's tooling for lots of things (like git, or file browsing) are not as advanced or comprehensively scriptable. It's not uncommon for me to have both zed and emacs buffers attached to the same remote development context.
So, that's what development tends to look like to me. One or two graphical editors, on my main desktop. Many persistant projects mapped to running containers (and maybe remote hosts), with various different projects open in them for work. I get a persisting, consistent user interface over diverse projects, all of them in a full linux environment, each completely isolated from the others, but networked.
In my current job, we're using Windows, and the whole Microsoft business stack, and we have a IT managed network. It's a bit of a change from what I'm used to. But, unlike a lot of software developers, I've found that I like change! (Often, you learn stuff. So what have I learned?)
I've been issued with a pretty nice Microsoft Surface branded laptop. The hardware, at least, is nice (and higher spec than any of my own current computers). The software is, of course, Windows, which I remain suspicious of using. The surface runs it like a champ, of course.
Interestingly enough, modern Windows understands that the majority of software deployment is now to linux, or linux-like environments, and the developer tools include an integrated linux-based toolchain. It's called 'Windows subsystem for Linux' and it's on it's second major version - WSL-2. WSL-2 basically integrates a virtualized linux kernel running inside the windows enviroment, which can be used much as I've described my container approach above - you have a virtual linux host, with it's own filesystem and processes, and a convenient interface between this and the host system.
You can run your graphical applications, and even your IDE (Visual Studio Code, presumably :-)) , and browser (Edge, your AI-powered browser!) in your graphical desktop, and have a local 'server' for developoment. WSL integrates with Docker Desktop for Windows, allowing your docker containers to run natively in the linux environment, and you can even install and run multiple instances of WSL containers to have different isolated linux 'back-ends'. It's a compelling work narrative, but it is founded on the idea that your goal state is using Windows for all your user-facing software and interface. Howerver -- What if you don't want to?
Because the WSL environment is an optimised full linux VM, it seemed to me that I might even be able to treat the WSL environment like a remote linux system, and move my existing workflow over - use a linux desktop to remotely access a local linux "server", that just happens to be Windows, and run development inside there using my typical approach of multiple contexts isolated into separate system containers. That's more like my idea of best of both worlds - my work computer can be a locked down managed enterprise client, I can get good use from the fancy hardware, but still maintain the toolchains and client interfaces I'm most comfortable using. Assuming, of course, that I could get it all to work...
Well, it took a bit of fiddling, but I'm here to say it works, well! my Windows Laptop runs on my desk, my software projects run on it inside incus containers, and I access them from emacs or zed or terminal windows, on my ancient creaking linux desktop system. I can easily run as many of these containers as I can fit into my 24GB of WSL (actually quite a lot of headless containers, in my experience) - voila! My Windows laptop is now a cloud host provider!
Here's a detailed walkthrough of how I set it all up. Please note that you will need a local Windows admin account to make some of the necessary configuration changes to the Windows side of things, but aside from a couple of privileged config changes, all of this can be then run as a non-administrator user account, which is another great benefit.
(Because I set this up originally a year ago, my instructions are written from before Debian 13 was promoted to stable, which is why you'll see me using 'Bookworm' in a few places.)
Firstly, you need to install a WSL2 environment. I picked Debian (which is supported), and I initialised this. I then system upgraded the Debian installation from bookworm (12/old-stable) to trixie (13/testing) using apt, because incus is packaged as part of trixie. I was then able to install incus using apt, and follow the incus initialisation and setup instructions from the project configuration page. I quickly launched a couple of bare bones containers to check that things were working as expected.
incus and incus-admin groups (check this with the id command), you should just be able to run incus launch images:debian/12 - this should download a base debian image, and launch it with a generated container name. You can see it running with incus list , and launch a shell within it with incus shell <container-name> - Please read the lovely docs for more such hints, this post is not intended to be an incus user guide ;-)
The next thing I did was add some additional WSL configuration by creating a .wslconfig file in my User home directory on Windows - this is a plain text ini file. I was pleased to find that Notepad.exe still exists in 2024, and can be used to create this file :-)
[wsl2]
memory = 24G
nestedVirtualization = true
networkingMode = "mirrored"
this is relatively self-explanatory - I'm giving most of my 32GB of RAM to the linux VM (because i'm not really using the windows side), I'm enabling nestedVirtualization, although I don't think this is a prequisite for running incus containers, it sounds like something I'll probably use at some point. Finally, and most importantly for this case, I'm setting the networkingMode up to use 'mirrored' networking mode - this replicates the windows networking devices and configuration inside the linux VM, meaning we can connect directly to the linux system from the network, without having to set up port forwarding or anything like this.
Once you've created the file you need to restart WSL in order for it to take effect. The easiest way to check if it's working is to look at your available system RAM in linux using free - it have changed to be 24GB. The next stage is to setup windows to allow client connections from the LAN.
We also want to be able to connect to our virtual linux box conveniently from the LAN. This requires a few things. Firstly, we need a stable network address or name. Secondly, we need to allow incoming network connections. This part requires enough Admin privileges on the Windows host to change networking settings.
I redefined the network adapter settings in Windows to use a static IP for this LAN, and added a DNS name for it in my local resolver. I set this network configuration up as a 'Private' network profile. The next step is then to configure the Hyper-V firewall on windows to allow incoming connections to pass to the VM. Running a powershell window as admin, I added firewall rules to allow this for the private network profile. In this way, I can ensure that the host is only accesible like this on trusted networks.
The WSL vm has a fixed identity string (the VMCreatorId) , a GUID, which is 40E0AC32-46A5-438A-A0B2-2B479E8F2E90, so the command you need is something like
Set-NetFireWallHyperVProfile -Profile Private -name '{40E0AC32-46A5-438A-A0B2-2B479E8F2E90}' DefaultInboundAction Allow Now incoming connections on the windows IP interface will be receivable in the WSL VM. Enable sshd on the WSL environment, and then check that you can ssh to the network address. You should get a login inside the WSL environment. If you run incus list here, you should see any running incus instances.
You can now access incus containers on the WSL instance from a remote emacs, if you use the incus-tramp method, and tramp pipelining. Access a path like /ssh:[email protected]|incus:me@container-name:/path/to/project in emacs and everything should be there. Relying on additional tramp stages for proxy chaining, although it's a very neat trick, can bring problems with performance, and reliability, and it is more simple to push the extra hops into the ssh layer.
This involves a bit of glue code, which looks hideous, but works very well.
Setup 'Control Master' for ssh, which allows repeated ssh connections to the same host to re-use an established ssh session. This will speed up the time taken to open new sessions, and noticeably improve the responsiveness of tramp for ssh remotes. Secondarily, use a ProxyCommand directive to connect a single ssh connection to a proxy session. Finally, you can use wildcard rules with a host suffix matching a certain host pattern straight through into an incus container on a specific host. Here's the relevant entries from my ~/.ssh/config
Host *.wsl
ProxyCommand ssh my.windows.box incus exec $(echo %h | sed 's/.wsl//') --user 1000 -- /usr/bin/nc -q0 localhost 22
ForwardAgent yes
Host *
ControlPath ~/.ssh/master-%h:%p
ControlMaster auto
ControlPersist 10m
In ssh configuration files, the first applicable setting is the one that will be used, so we should order the file from most specific towards most general.
Here, we're using a fake 'domain' of .wsl, and then converting the command to an ssh to the windows host, that immediately launches incus, getting the container name by chopping off the '.wsl' from the provided hostname and running 'netcat' in the container to proxy our ssh session to the ssh server inside the container. With this little piece of ugly glue, we can run ssh container-name.wsl and immediately get an ssh session directly into the running container called container-name
The control master block ensures that we re-use an established ssh control session for all connections to the same host, and persist it for 10minutes after the last connection exits, to improve reconnection times.
With this piece in place, we can access files, shells, and processes from emacs buffers, using a tramp path of /ssh:my-container.wsl:/path/to/project - or laucnch a zed session in a remote project directory, using their ssh 'remote project' feature.
The main, and perhaps the only real downside of this approach is that Windows likes to restart, often. Usually in batches once or twice a week. This is a combination of updates from remote IT and Microsoft I suppose. Rather than get too aggravated about it, I prefer to think of it as a free chaos monkey.
I can alleviate most of the pain points by making everything as restart-able as possible. WSL can be set to start as soon as you login by tweaking a few settings in the cmd.exe application
cmd to start on loginThis means that after a boot all I have to do is login to resume the WSL state
incus configThe local "staging" version of any webservices I am working with I typically run in Docker , inside the inucs container (as my user account) - i usually write a shell script to launch docker with the right port forwarding and data persistence flags for whatever I want to be running (for more complex setups this could be a docker compose configuration) - I simply put this shell script into my user crontab, using the magic @reboot trigger directive to launch this script after multi-user init, as me, with just a one-liner.
with these configurations in place, all I need do is login to Windows (with my face 😘) to resume running services where I left them.
I've been writing a couple of things in hy again this week. What's Hy? It's a cute idea. It's a lisp that compiles? (transpiles? I never get the difference) to the Python AST. I guess the elevator pitch might be something like clojure but for python. So yeah, a rich, super stable class-tree sort of OO language, with enormous portablility and twenty-odd years of library support for everything you might want to do, but with a nice, dynamic, lispy language and a repl.
I've played with hy a little bit on and off over the years. Actually, when I was working at SMR, I actually deployed some in production. (Somehow, I doubt that's still a thing). Python is my go-to scripting language, because it's very plain, very portable, batteries included, somewhat modern, probably already installed everywhere I work. I try to use it for scripty things, rather than shell or perl or something. Lisps are my favourite programming language. I just like how it fits together. I know lots of people don't, and I'm fine with that, but I always enjoy it.
So over the holiday weekend I found myself wanting a couple of almost throwaway scripts, and I decided to reach back into the hy bucket, and give that another try. I wrote a script to grab my selfie tweets from a twitter archive, and a rough script to publish formatted micro-blog entries directly from the shell.
It was a fun exercise. Hy has moved on a bit since I last tried. (They seem to have removed let, and car, and cdr, and lambda which I feel funny about), but by and large it works really well.
I don't think I would choose to use it to build any complicated systems. (Typically this is true of Python as well to be fair). I'd love to see something like an idomatic web framework in it. I could imagine using it to build serverless workers over something like apex up or chalice perhaps. I should totally try that!
I am not really very good at it yet, so I doubt I'm writing optimal programs. My scripts often look like Dr. Moreau designs halfway between a python script and something more lispy. This could well improve as I understand the underlying sequence / itertools glue a bit more, I'm often routing around confusing sequenced things. I absolutely enjoy writing little scripts like this in it, and I think I maybe enjoy it more than I would if I was writing plain python. I gave some thought about why this might be and I think I figured it out.
It could just be as simple as being all about the code editing. Python, and it's whitespace delimited blocks, is fine, and super readable, but it's always slightly fiddly to edit. Some of this is my toolchain, I'm sure. There's a lot of bells and whistles you can glue over emacs for Python work, and they're pretty good, but I do always find it a slightly fiddly experience. Balanced expressions and sexprs though are obviously an absolute joy to edit in emacs, alongside an embedded inferior lisp repl, and although it's nowhere near as integrated an experience as using slime with a "real" lisp, it's closer to that than editing Python ever feels, and for me that's a significant productivity win. So I think it will stay in the toolbox.
I recommend Hy to anyone who is interested in interesting lightweight languages, especially scripting languages. Obviously it's particularly relevant to anyone who likes python or lisps, even if just as a curiosity. If you work with Python and like using emacs though, and like the sound of 'Python but with structured editing' I would strongly recommend you look at how it might integrate into your workflow.
For the past year and a bit, I've been relying on a one-user GoTosocial server for my fediverse participation. Fediverse is the 'well, actually' technically correct name for the social network protocols that power an overlapping set of free, distributed social networks that a lot of people just call 'Mastodon'. Mastodon is the largest and most popular server software used in this network, and got a significant bump in popularity when that crazy space junkie guy started hacking on twitter.
Mastodon is a large Ruby on Rails project, with the typical kind of architecture you might expect from a classic LAMP-adjacent dynamic web thing that's used in production to run instances with thousands and thousands of active posting user accounts, and a hefty server footprint.
Gotosocial is a fediverse server that specifically targets a lower footprint installation. It's written in Go, which while not being the kewlest platform to build a modern web server application in, is to my eyes, a pleasingly pragmatic choice. (Something I often like to say is 'Go is actually kind of a DSL for building small network servers in'). It also targets full mastodon compatibility, so it's a drop in replacement for a mastondon account, and much simpler to run if you were interested in having your own fediverse service.
Whilst Gotosocial has a modest footprint, and a few moving parts, it's not without some interesting technical architectural decisions. In one of its simpler installable forms, rather than use an external relational database like PostgreSQL, it just uses good old SQLite3 😍 - and rather than pay the CGO / boundary penalties for linking directly into SQLite as a shared library, it can actually run SQLite as a contained WASM process inside the go application, using the Wazero runtime
I adore everything about this approach, it's exactly the kind of mad science I'd try to get a simpler working service. End result is you have a single static binary that you can run and install, and it manages its own fully compatible SQlite3 database store in-process, without any install-or-link-time dependencies.
So it's super simple to install for me on linux, I simply need to unpack a binary linux release tarball and then launch the newer binary with the old database file. Gotosocial applies database migrations on startup.
Here's their offical upgrade instructions taken from codeberg for the binary release
It's about as simple as a manual upgrade can be.
Well, aside from scripting it, I think there's one small improvement that can be made. So far as I know, GoToSocial doesn't (yet?) run auto vacuum on its SQlite database. VACUUM on SQLite is a necessary maintenance procedure that's used to refresh, compact and optimize the database backing store after it's been amended in use for some time. You can think of it a bit like a 'defrag' or a 'garbage collecter' for your database.
Without auto-vacuum, vacuum is necessarily a blocking operation, you will block all other database changes until the vacuum is done. As such it's ideal for downtime. So vacuuming your GoToSocial database when you upgrade is a good idea, although it does extend your service downtime by a couple of minutes.
So, as well as copy your database to a backup, I suggest you also connect to it, with the sqlite3 command and run a complete VACUUM. But wait, we can be even cleverer.
Vacuum already makes a complete copy of the database. Go back and read the VACUUM documentation I linked above. You might also notice that SQLite VACUUM supports a 'VACUUM INTO' form, which materializes this vacuum copy information into a fresh database file.
so my amended system upgrade is like this, pretending for the sake of example that it's a manual process.
/gotosocialsystemctl stop gotosocialgotosocial binary to a versioned backupgotosocial.sqlite to a versioned backup name e.g. gotosocial.backup.sqlitesqlite3 ./gotosocial.backup.sqlite commandVACUUM INTO 'gotosocial.sqlite' (i.e. re-creating an optimised gotosocial database)systemctl start gotosocialjournalctl -f -u gotosocialI'm sick of Twitter, folks. I've decided to do something both mild and drastic about it. For 2018, I have resolved to stop using it.
I am not sure what it is for anymore, it certainly doesn't feel like it is for me. I think I've been disengaging slowly for the last couple of years, and in 2017 I repeatedly found it too aggravating, and depressing to engage with. I think I would have already ragequit, had one of last year's resolutions not been that silly selfie thing. Thus a seed was planted about resolutions and exits. Brains often work that way. (Referendums are silly though)
I was late to twitter. I downloaded my twitter archive, whilst I was scraping out all of the 2017 selfies, and apparently my first tweet is from Dec 2007.
gearing up to watch new BSG
— cms the vampire queen (@colinstrickland) December 18, 2007
I was late to Battlestar Galactica as well.
I probably spent a little while reading twitter before registering, although I don't remember anything specific. I can't remember why I signed up in the first place. Looking at that first month of odd, stilted entirely quotidian status posts, I can tell I'm working on Logical Bee, mostly alone, babysitting that dog. It's winter. Maybe I'm lonely? I have a dim memory of thinking it was pretty dumb for a long while before getting involved at all. I remember fiddling about connecting it to things, and experimenting with SMS tweets and emails. I don't think it really clicked for the longest while. I remember a sense of a clique I wasn't ever going to be able to get into. That first wave of web-natives, younger than my generation. More entuned to a web of application services and APIs than hypertexts and data servers. I remember tweetups being a thing, and a Bristol one being announced, and spending an hour or two before deciding firmly I wasn't the kind of person that went to that kind of thing. I quite wish I had gone now. I didn't used to be a very good joiner-in of things. I'm not much better at that now. A little bit, perhaps. Now I know to try.
It took the longest while, but eventually it clicked. I liked the lightness of it. It was sort-of social networking, but social networking at arms length. Lots of irony, lots of whimsy. I just remembered the earliest phase of my binning Facebook was to convert my facebook to just echo my tweets back into it, for the muggles to read. I remember being very snobby and standoffish about things like hashtags and @replies. My first reply wasn't until August 2008.
@davehodg , also for consideration; twot, and perhaps twerped
— cms the vampire queen (@colinstrickland) August 12, 2008
To Daveh! Either I don't know how to reply yet, or the Twitter archive has incorrectly threaded that reply back together. Either seems plausible.
I didn't use a hashtag until May 2009. Even then I was repurposing "get off my lawn" meta-commentary. Amused to see that my next half dozen hashtags are complaining about moonfruit's use of them for viral marketing. Many years later I ended up working there for a season. Again we see the seeds are sown, and the fruit is reaped.
Still fascinated by how rapidly people have started to game twitter trends, and thoroughly amused by #theBNParetwats
— cms the vampire queen (@colinstrickland) May 12, 2009
Not too ashamed of that one. It's interesting looking back at tweets like that, I have a sense that the prevailing vibe of Twitter at the time was that the cool kids were beating out the idiots. I don't get that vibe off Twitter now.
By this point it was clearly very firmly entrenched in my daily desktop routine. Once I got hold of smartphones that could run twitter, I think my usage ramped up. I remember by the time I got to last.fm, I was tweeting all the things, curating a couple of hashtags (#fantasypeelsessions for serendipitous word groups that sounded like band names, #fisharecool for cool fish facts), running multiple joke twitter accounts, writing bots, and generally really enjoying it. I remember when I got to Makeshift, and twitter seemed to be used as the wiring behind at least half of everything there, it then seemed like a necessary internet plumbing for web apps. With hindsight I think that was the peak. It was downhill from there. I don't like it any more, I have detected an opportune moment, and I have decided to leave. At least for one year.
I'm not going to use this post for arguing about why I think it's broken. One of the largest problems I have with it is the sheer concentration of negativity. And one of the reasons I want to move away from it is to focus on building things that are more positive. It's not just Twitter. I'm pretty broken-hearted with the state of the web in 2017 - it's very far from what I signed on to help build as one of those idealistic Gen X web 1.0 types. And again, rather than just bemoan that, I'd rather start focusing on ways to think about fixing that. And for me, in 2018, this means I'm going to go small, and focus on building things and content I can own, in the sidelines. I expect I will be updating here more. I plan to double-down a bit harder on indieweb things, and federated stuff. POSSE all the things. Death to silos. I've been experimenting with micro.blogs and mastodon.social, and I want to play more with beaker and dat, and blockstack and IPFS and other idealistic p2p proto-webs. Maybe even frogans?. The real web looks more like that. Maybe I can help figure out how to make it a bit easier for everyone to clamber onboard.
First off, that's flattering, almost-certainly-entirely-imaginary-cms-fan, thanks! I like you too! Occasionally some of my tweets get as many as five or six engagements, and I do enjoy keeping up with some lovely people. Some of whom I met or perhaps only know through twitter. I'm sorry if this feels like a breakup; It's not you, it's me, as they say in the rom-coms. (Actually, I'm not dumping anyone.)
Something else I want to push for in 2018 is better quality, stronger, social engagement. I want to cultivate more real contact, more high bandwidth engagement and connection with all the good people. This can work two ways of course. If you only really interact with me on a tweet by tweet basis, and you think you're going to miss that, then do please reach out. We can have coffee, or get beers, or just go fish in a lake or something else entirely. And I'm going to be pushing myself to reach out to more people in turn myself, something I'm astronomically poor at. Please help me with this if you can!
IRL networking I plan to ramp up a bit. More meetups, tech and maybe otherwise. Maybe I'll rescind my conference ban. Maybe I'll start some of these things, or start helping to organise them more.
I'm not doing an *infocide*. As well as publishing things hanging from here, which has plenty of RSS feeds, if you can still figure out how to integrate those into your workflows then I'll probably never be very far away. Also, if you look at the home page, there's a list of dozens of other not-Twitter platforms you can stalk me on or connect to me via (maybe we are already!) - If my plan comes together, I hope to be syndicating and updating the useful ones of these more actively.
I don't intend to delete or remove my twitter account, and I will set things up so I still get notifications, so nobody gets ignored. I might even automate some notifications to my twitter feed about updates to things elsewhere. I'm just not going to be participating as a human. I expect I will remove all the apps, so my turnaround on mentions might slow right down.
If you're in the select category of people who only know how to contact me with twitter, there are many options. I haven't changed my phone number, should you know me well enough to have one of those. If you're looking for a way to DM to me, I cannot endorse keybase strongly enough. I think they're trying to do something really interesting, and could do with some more network effect. Sign up to keybase, and keybase message me, I love getting keybase messages, and I always respond. Invite me to your keybase groups! Also, please share your slacks and your newsletters and your mailing lists with me, if you think I'd like them, or they'd like me.
Email still works, and I still read it. My address is even on my website.
Finally, if you're reading this, and we've Twitter interacted in some way, let me say a goodbye for now. If I was annoying, or argumentative, I'm sorry, I can be hard work soemtimes. Maybe some of that might have been caused by the platform? If I was fun or charming or interesting, then let's work to stay in touch! If you don't really care, you're not even sure how you got here from off of twitter, that's cool too, maybe I'll see you again in a year from now.
With all this focus on RSS generation for micro blog, I've been optimising my engine. I've learned how to use SBCL's profiler, and I have shaved a third off the cost of generating indexes

It's been a month now, and I ought to be used to it, and in many ways I am, but in surprisingly many ways I'm still not; I don't have a dog anymore. He got too old, and he got too sick, and tired, and uncomfortable, and he had to be put to sleep, back on the 28th of November. How does it feel? Terrible.
It was an enlarged heart that did for him. Poetically enough, his heart was just too large for him to carry on. The photo above is taken on the last morning, before I headed out to work. I knew there was very little chance he'd be coming back from the vet's appointment later that day. We had a little conversation and I carefully explained to him that he was a very good dog.
Of course he was actually a terrible dog. A brilliantly terrible one, as most dalmatians are born to be. He'd not really been himself for a couple of years, stumbling about and complaining about most things, but right up until the last couple of weeks he was coping mostly, and remained good company. In his prime though, that dog was an athlete, who used to literally fly, and if I open my mind's eye a little, that's what I can see, streaking around the Bristol countryside, barely controllable, raiding bins, and laughing at you, over his shoulder.
I don't really know what to write. I have to write something though. This website, which has been knocking around for fifteen years or more, only really took initial form as a rudimentary 'blog' so I could share dog photos with his burgeoning fanbase. Most of that has bitrotted now, but when I feel better I would like to clean it up some. So I can't really even let go of him without marking some notice here. I don't need to trot out all of the anecdotes, they're probably dull and too personal. After all, outside of my immediate circles, he's just some bloke on the internet's dog. To me, and to some of his internet fans though, he's the best dog in the world. Every single word of that is true.
Should you wear nice underpants when you feel ill, or 'I guess I don't care about anything' ones? These are the questions
When you have, as I have, a race condition in posting that exists somewhere between systemd, rsync, bash, perl, and that's before you even get to the CMS, it is probably time for some refactoring
I posted about yesterday's post on LinkedIn, because it seemed like a low-key way to get people to consider my CV. Although I'm not exactly job-seeking at the moment, we ARE having a big surprise technology function re-org, and it feels like a great moment to be prepared for a role change. So, if you're reading this and you think - hey that guy sounds like someone I'd like to work with and you're hiring people for something fun, now might be the perfect time to reach out 🙏
Anyway, LinkedIn appears to be having a bit of a cultural resurgance of late, which is interesting. People are using it a lot more like a general purpose social network than ever they used to. I have a few thoughts about why but they can wait for a different blog post. I kind of like it, because I'm always sincerely happy when people make "content" 🤮 rather than just passively consume stuff. A lot of the content is a bit awkward, because there's obviously a motive toward self-promotion, as so much of the LinkedIn audience are job seekers, recruiters and sales people, but still my feed quite often has interesting content popping up. It's kind of 'business instagram'. Instagram but all the influencers are dads, dad-dancing at the school reunion disco. It's honestly not without charm. Not all posts are equally enjoyable though.
AI Hypers! Of course LinkedIn loves AI hype! Now, I'm quite fascinated/entangled/repelled/enchanted with the AI boom myself. We're certainly having an industry moment, and like each crazy boom cycle I've seen in this domain, it's a bundle of awful things mixed in with amazing things, and fun things and tragic things all at the same time. One thing is certain though, there's a lot of AI opinions surfacing on LinkedIn right now. Too much I think. They're a bit repetetive, and I'm not always seeing that much valuable content from them.
Jane Q. Businessguy posts something like this. (Not their real name. I made them up. I made the content up. This is satire. I am British, cynical sarcasm is what we do)
Yesterday I blew my own mind. I was thinking out loud in the bathroom, and minutes later, after a couple of deep inhales, I had implemented one basic Selenium script from a prompt transcribed from a voice note that runs our smoke tests automatically and honestly? We don't need QA teams anymore!!! Think about it: automation = no bugs. It's that simple. The future of software is here and frankly, any company still paying QA professionals is throwing money away. We're living in 2026 but some of you are still hiring like it's 2015. This is the kind of paradigm shift that separates the industry leaders from the dinosaurs. We've moved past the era of "manual testing." Those days are OVER. If your organization hasn't eliminated your entire QA department by Q2, you're already behind. The math is simple:
Automation = efficiency Efficiency = no QA needed QA people = legacy cost
Welcome to the future. You're welcome. Don't @ me if you're not ready to hear hard truths.
#Innovation #Disruption #FutureOfWork #Automation #TechLeadership #HotTake
I'm pleased for Jane, although I'm quite suspicious that something like this ever actually happened.
Wait! It didn't, I made it up! I made Jane up too!
Phew. But what if some of the LinkedIn posts I'm seeing are also... made up. Some of them might even be made up by AI. Could I do something about this?
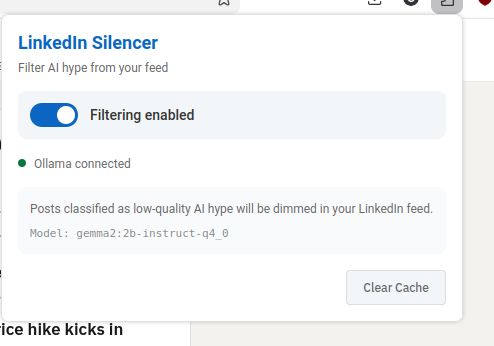
I could really do with some kind of content filter. It's a shame LinkedIn doesn't allow me to train my own algorithm. Maybe something else could do this though. Maybe this is one of those mythical use cases that are great for AI?
LLMs are really well suited to content classification. I guess if I could find a way to put the LinkedIn content through an LLM and prompt it to identify boring unispired AI cheerleading, I could then reduce the frequency of it. Or maybe just filter it out. I guess I need a semantic ad-blocker. I wonder how hard that could be to build.
Time to talk with Claude. I fire up claude desktop.
How could I build a plugin that filters LinkedIn Posts ? I'd like to use an LLM to build something that removes low quality posts boosting AI or LLM from my feed, ironically
Claude grinds away on this for a few seconds, and pulls out a couple of options. The architecture suggestion is a browser extension. Makes sense. I've built browser extensions before, they're kind of annoying, but the best way to get code control over live browser content. OK Claude, I'm listening..
I scroll past the typescript skeleton code it's printed, unasked for. Another thing I don't want to do is let random LinkedIn content posters burn tokens and the planet for me on some kind of expensive remote AI API. But my (fairly old) desktop machine has a moderately OK recent-ish radeon (AMD Radeon RX 7600 XT iirc). I've used this quite a bit for playing with local models using transformers or llama.cpp or ollama I should be able to do sentiment analysis and tagging on this in something close to real time I reckon.
Ok, I hit the bottom of the claude window and follow up with this
let's do this - generate me a prompt for claude code. An extension - I'd like the UI to just dim post content on a linkedin home page if it strongly matches the criteria - lets use ollama and a small local model like gemma3:12b-it-qat
here's what claude gives me. Let's just pass that into Claude code, see where it goes...
Ok, so I make a bare directory for the project, called 'linkedin-silencer', chdir to it and run claude , which launches vanilla claude code, updated today, no plugins or user config. Let's raw-dog this. I plop the claude generated prompt into the terminal, and sit there for five or six minutes agreeing to everything. When it's done I ask it to git init and commit what it has and then I quit claude code. Let's have a look at what it's generated for me in an editor.
I have an ongoing love/hate affair with the amazing zed editor. Much more on the love side than the hate side. What I particularly like about it is a couple of things
zed really deserves it's own blog post at some time, but once again this is not that blog post.
zed fires up on my project, and I immediately see a bunch of red diagnostics. Oh no, my code is full of bugs I guess. It's not even my code! 😭
Yup, this is still sadly true. This is one of the things I think upsets a lot of people who don't like to engage with them. The magic genie still doesn't perfectly perform the magic trick. I guess it would be cool if you could just say 'hey genie, make a thing that's awesome' and trust that it would just happen, but we're not quite there yet.
To be fair to the robot, I don't write code without bugs myself. Also, it takes me much much longer to write my bugs. And, because I'm a selfish egotistical human programmer, I tend to not believe that I've made any bugs and it's sometimes a bit difficult to get my head into the right mode to debug them, because I can't immediately conceive of how or where they would exist. However, I totally get that from a certain point of view, this is breaking the enjoyment model of programming. Lots of people like writing code. Lots of people hate debugging code. Me too, to a certain extent. So now I have to debug maintainence code written for me by a dumb robot. This seems like a bad trade.
That's not the only way to look at this though. One of my big problems is sustaining the motivation to carry through with ideas some of the time. (I have that kind of brain). Ideas are pretty cheap, but iterating on them and executing them can be quite costly. And I already wrote a bunch about the idea of higher order tools as a way to reduce programming adjacent work . This is key to the appeal boundaries I find with the current generation of assistants. The most useful stuff they offer is a way for me to delegate the really boring bits of work like 'setting up a tsc project' , or 'building a nice looking README.md' , or 'refactor that submodule name'. And they can deliver on some of this, some of it really well. Right now though, we have bugs. Well, at least zed will let me use some more assistants for debugging. Let's see how far this river goes.
Zed gives me the typescript diagnostics on a separate pane. It's not too bad. there's about two dozen errors, most of them type assignment things.
One thing pops out, it's not happy that I'm using 'chrome' apis for things like local storage. Browser extensions are a bit odd. They basically work like a little web service running in your browser. There's roughly 3 bits to it - the content script (the UI stuff for the extension, works a lot like a traditional JS document), the background service (a service worker, a javascript that runs in the background inside your browser session), and the local store (a way to get data persistence for your plugin, it's basically a KV store kind of thing wrapped over SQlite) - I assume the apis for these are something i need to add to my typescript compiler configuration - they're not part of normal JS I guess.
I pop open a zed assistant window, set it to 'ask only' and 'claude sonnet 4.5' and type
@service-worker.ts - why are there so many diagnostic errors about missing 'chrome' - I'm trying to write a browser extension. I suspect I'm missing some node module or type definitions?
The assistant pulls in the diagnostics tab output and says
The issue is that TypeScript doesn't know about the
chromeglobal API. For browser extensions, you need to install the Chrome extension type definitions. Let me check your project setup:
and tells me I can fix it with
npm install --save-dev @types/chrome
this sounds at least 99% right to me, so I do it. Yup, fixed. I commit this change to git.
The next, and only, non-type error is a bit odd 'duplicate function' against a function called classifyPost , which is a function in the service worker that takes in post text and returns the classification - either 'KEEP' or 'FILTER'. I can see that there's also a function with the same name i the content script. I guess that all the functions in the project are getting combined into the single top level namespace. There's no implied scope then. I guess I could fix this by changing one of the function names, probably using 'rename symbol' in the language server. But maybe there's a way to namespace things ?
I bring the assitant back and ask it
there's a name collision because in @service-worker.ts there's a @classifyPost() but there's also a @classifyPost() in the client/side content code. why is this an error , should these be using some kind of namespace mechanism ?
Claude says yeah, these files are getting pulled in as scripts not modules and everything is in the global scope. It suggests that if I simply add empty 'export ' statements to each they'll be loaded as modules. All I can really remember at this moment about ECMAScript modules is that they're a bit weird, relatively recent, and there's a few different ways to provide library scopes, and some back-compatibility quirks. This suggestion sounds about 75% right to me (hell, I'm no JavaScript expert), but the change is so small I figure it's worth it. It works, so much as the errors go away. Ok, makes sense, i don't need to share any symbols. Let's commit this.
The next small tranche of errors are all about assingments, and I can see they're all coming from storage fetches. It looks like claude has implemented a local LRU cache or something, using the aforementioned local store APIs, and it's pulling values out of this in helper functions and not bothering to consider that the key lookups might return nulls. Classic type fun with database nulls! Well, I know enough to fix this, so I just manually add some intermeidate x | undefined types to the fetches, and put if guards around the reads and return paths. Close enough for jazz
The final error flummoxes me a bit. There's a loop around the elements fetched from the page Document , and it's complaining that the ChildElementList type isn't presenting as an iterable. Sounds legit, but also the code looks fine to me. Assitant time again.
can you tell me what's wrong about this loop - it thinks the NodeList isn't iterable @linkedin-filter.ts
The assistant explains that my typescript configuration isn't including the necessary types to make NodeLists fully iterable. I hit a traditional search engine for confimation, and then I add "DOM.Iterable" to the lib: array in compilerOptions . Zero errors.
I pop open zed's integrated terminal and type npm run build. It builds!
I'm feeling a bit cocky so I decide to try the extension in firefox. I load it manually using the dev tools as a local unpacked extension. Firefox refuses, because it says the service worker can't be found in background.scripts . I've seen this bug before though, manifest v3 support is a bit variable between browesers.
I add background.scripts = ["service-worker.js"] to the manifest and rebuild and install.
It loads!!! What have I done?! Look on my works, ye mighty, and despair.
I quickly load my Linkedn Page. It's full of AI hypers though 😢 The extension doesn't work.
I pull up the extension UI from the toolbar, and it's enabled. But there is a little red error message saying 'ollama not connected'. Oh dear. I check ollama and the server is running. More debug time.
I figure this one out manually using the web dev tools on the service worker inspector, and playing in console. The requests that are being made to ollama are getting 403. Huh. I wasn't expecting that, it's some kind of auth problem. Ugh, I bet it's CORS stuff. That's always tricky with extensions, they're typically requesting from a weird origin.
A bit of searching and a quick chat with claude desktop, and yup, ollama is strict about request origins by default in server mode. I can't blame it. After a bit of fiddling with ollama config, and lots of cursing at systemd overrides. I figure out how to configure Ollama to trust a specific origin (firefox has generated an origin url for the extension automatically, like moz-extension://foadfadfoasdfasldjfadslfja) I can trust this origin really, because its an extension I've installed myself (although I'm not leaving it on like this until I've properly read all the code, i've been running it in the debugger and i can see the requests are pretty straightforward).
I spend about 35 minutes messing about with systemd and restarting ollama before i get the recipe right (this is actually the longest bit of debugging) , and then all of a sudden, I notice the requests have switched to 200 and I reload linkedin and ... almost every post is dimmed and tagged as AI hype. Hmm. It's sorta working. Looking at the posts though, a lot of them are just a bit hype, rather than AI hype. So I adjust the prompt I'm sending, and everything seems good. I now have a browser extension that tags and dims annoying AI hypefluencer posts.
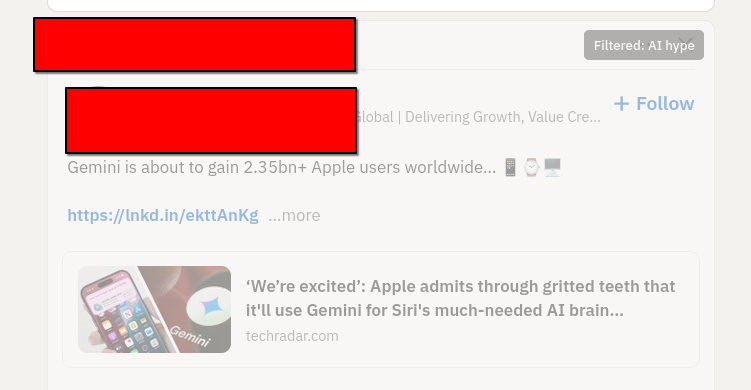
I've pushed the whole thing to GitHub, if you're interested enough to peruse. I'm sure it still has plenty of errors, but it works well enough for a blog post, and maybe well enough that I'll refine it into something a bit more useful. I haven't even tested it in chrome browsers.
Now the only thing left to do is to write an hyped up linked in post about my little project, and see if it works on my own content!
Does anyone know if eating your own bodyweight in Stilton is a good way to clear up Xmas flu?
 I think she is smitten.
I think she is smitten.  introducing Snoop Dogg, a three year old Bedlington rehome
introducing Snoop Dogg, a three year old Bedlington rehome  This was a great Xmas read, although nothing like what I was expecting
This was a great Xmas read, although nothing like what I was expecting 